머신러닝 용어 ( Data Point, Sample, Instance 등 ) Attributes : 속성 Example, Sample : 사례 Data Point : 다차원 공간에 위치로 표현되는 벡터라는 의미에서 사용 예를 들어 붓꽃 데이터는 150개의 Sample(사례)를 가지며, 4개의 Features(특성)을 갖는다. Instance : 인스턴스. 1 sample이 여러 개의 속성을 갖는 것 (각 사례를 개별적인 특성을 갖는 단위로 묶을 수 있다는 의미로 사용) 머신러닝 (Machine Learning)/머신러닝 기초 2021.04.27
머신러닝의 역사 [케라스 창시자에게 배우는 딥러닝] 참고 확률적 모델링(Probabilistic modeling) : 초창기 머신 러닝 형태 중 하나로 통계학 이론을 데이터 분석에 응용한 것. 가장 잘 알려진 알고리즘 중 하나는 Naive Bayes (나이브 베이즈) 알고리즘 이다. 나이브 베이즈는 입력 데이터의 특성이 모두 독립적이라고 가정하고 베이즈 정리(Bayes' theorem)를 적용하는 머신 러닝 분류 알고리즘이다. 이런 형태의 데이터 분석은 컴퓨터보다 앞서 있었기 때문에 수십년 전에는 수작업으로 적용했다.(1950년대) 이와 밀접하게 연관된 모델이 로지스틱 회귀(logistic regression)이다. 이 모델은 현대 머신 러닝의 시작으로 여겨진다. 나이브 베이즈와 비슷하게 컴퓨터보다 훨씬 오래 전부터 있.. 머신러닝 (Machine Learning)/머신러닝 기초 2021.04.22
앙상블 - Random Forest 관련 포스팅 - 앙상블(Ensemble) 앙상블(Ensemble) 1. 앙상블 방법들(Ensemble methods) 앙상블은 분류에서 가장 각광받는 알고리즘 방법 중 하나입니다. 딥러닝을 제외한 정형 데이터의 예측 분석 영역에서는 앙상블이 매우 높은 예측 성능으로 인해 gggggeun.tistory.com 관련 포스팅 - 앙상블 - 배깅(Bagging) 앙상블 - 배깅(Bagging) 참고 : KoreaUniv DSBA 영상 다양성(Diversity) Implicit Diversity Explicit Diversity Description 무작위의 서로 다른 training data 여러개를 제공하면 학습 결과도 달라질 것 다른 구성원과 실질적으로 다른.. gggggeun.tistory.com * 앙상.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.03.02
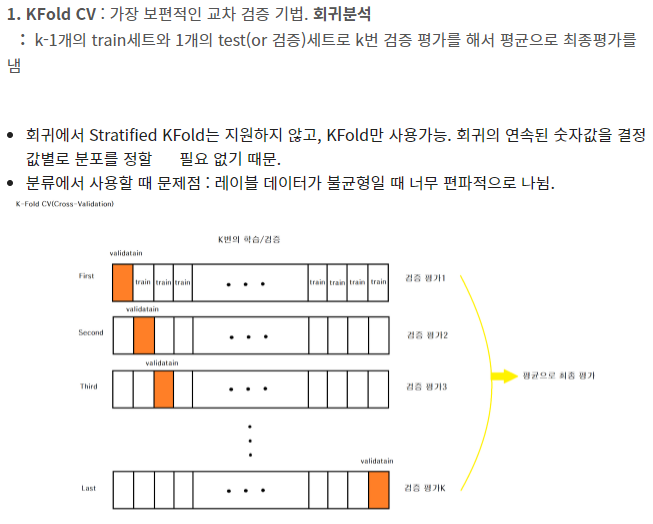
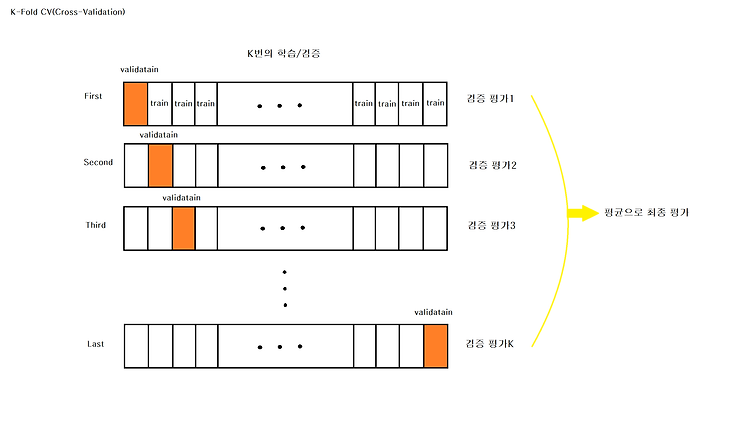
앙상블 - 배깅(Bagging) 참고 : KoreaUniv DSBA 영상 다양성(Diversity) Implicit Diversity Explicit Diversity Description 무작위의 서로 다른 training data 여러개를 제공하면 학습 결과도 달라질 것 다른 구성원과 실질적으로 다른지 확인하는 몇 가지 측정지표를 사용해서 이전 모델과는 다른 모델이 만들어지도록 유도하는 것 앙상블 알고리즘 Bagging Random Forest Boosting Negative Correlation Learning(NCL) *NCL : 다양함이 높으면 모델간의 상관계수는 낮아야한다라는 논리적 근거를 통해 나온 알고리즘 # 앙상블의 핵심 키워드 : Diversity 1. 데이터의 다양성 2. 모델의 다양성 1. KFold Data Sp.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.03.01
앙상블 - 보팅(Voting) 1. 보팅 방법 (voting methods) 하드 보팅(Hard Voting) 소프트 보팅(Soft Voting) 최빈값 평균값 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정 만약 레이블 값이 2개일 때, 레이블 1번 과 레이블 2번 중 다수의 레이블로 예측. 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정. 일반적으로 이 방법을 사용함. 만약 레이블 값이 2개일 때, 레이블 값이 1번인 경우의 확률의 평균과 레이블 값이 2번인 경우의 확률의 평균 중 높은 평균의 레이블로 예측. 일반적으로 하드 보팅보다는 소프트 보팅의 예측 성능이 좋아 더 많이 사용된다. 2. Result Aggregatin.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.21
앙상블(Ensemble) 1. 앙상블 방법들(Ensemble methods) 앙상블은 분류에서 가장 각광받는 알고리즘 방법 중 하나입니다. 딥러닝을 제외한 정형 데이터의 예측 분석 영역에서는 앙상블이 매우 높은 예측 성능으로 인해 많은 분석가와 데이터 과학자들이 사용합니다. (* 딥러닝 : 이미지, 영상, 음성, NLP 영역에서 신경망에 기반한 머신러닝의 종류) 앙상블 학습을 통한 분류는 여러개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도축하는 기법을 말하며, 당연히 단일분류기보다 신뢰성이 높은 예측값을 얻는 것이 목표입니다. 배깅 방식의 대표인 랜덤 포레스트(Random Forest)는 뛰어난 예측 성능, 상대적으로 빠른 수행 시간, 유연성 등으로 많은 분석가가 애용하는 알고리즘.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.21
분류 관련 Youtube 1. Decision Tree Decision Tree 설명 파이썬 사이킷런으로 Decision Tree 모델만들기 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.14
결정 트리의 과적합 (Overfitting) 시각화로 이해하기 결정트리의 과적합 문제를 시각화해 더 자세히 알아보겠습니다. 1. 사이킷런 make_classification 으로 분류의 표본 데이터 생성하기 - hyperparameter = defalt # make_classification 분류를 위한 테스트용 데이터 만들기 from sklearn.datasets import make_classification import matplotlib.pyplot as plt %matplotlib inline plt.title("3 Class values with 2 Features Sample data creation") #2차원 시각화를 위해 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성. X_features, y_labels = make_classifi.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.14
Decision Tree Graphviz ▶ Jupyter notebook 과 Google Colab에서 Graphviz 사용하기. (설치 및 사용법) velog.io/@gggggeun1/%EA%B2%B0%EC%A0%95%ED%8A%B8%EB%A6%AC-%EA%B7%B8%EB%9E%98%ED%94%84-exportgraphviz 결정트리 그래프 export_graphviz 1) 프로그램 설치하기https://graphviz.org/download/(설치 시 특별한 설치 디렉터리를 지정하지 않으면 C:\\Program Files\\Graphviz 와 같은 디렉터리에 Graphviz가 설치됨)2) Graphviz 파이썬 래퍼 모듈 velog.io 1. 결정 트리 그래프에 대한 설명 더 이상 자식 노드가 없는 노드는 레이블 값이 결정되는 Leaf n.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.14
결정 트리 (Decision Tree) 결정트리는 머신러닝 알고리즘 중 직관적으로 이해하기 쉬운 알고리즘입니다. 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것입니다. if/else를 기반으로 예측을 위한 규칙을 만드는 알고리즘으로 스무고개 게임을 생각해 볼 수 있습니다. 따라서, 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우합니다. 1. 결정트리의 구조 각 가지의 특성에 따라 Node 이름이 있습니다. 데이터 세트에 피처가 있고 이러한 피처를 결합해 규칙 조건을 만들 때마다 규칙 노드가 만들어집니다. 하지만 많은 규칙이 있다는 것은 곧 분류를 결정하는 방식이 더욱 복잡해진다는 얘기고, 이는 곧 과적합으로 이어지기 쉽습니다. 즉, 트.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.13
분류의 평가(Evaluation) (2) F1 score , ROC AUC - 분류의 평가(Evaluation) (1) Confusion Matrix, Accuracy, Precision, Recall 분류의 평가(Evaluation) (1) Confusion Matrix, Accuracy 머신러닝은 데이터 가공/변환, 모델 학습/예측, 그리고 평가(Evaluation)의 프로세스로 구성되어있습니다. 머신러닝 모델은 여러 가지 방법으로 예측 성능을 평가 할 수 있는데, 이 성능 평가 지표(E gggggeun.tistory.com 🎯 회귀와 분류의 성능평가지표들 지도학습 Baseline (기준모델) Evaluation Metric (성능평가지표) Regression (회귀) 실제값과 예측값의 오차 평균값 MAE , MSE, R^2 Classification (분류) Majorit.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.13
분류의 평가(Evaluation) (1) Confusion Matrix, Accuracy, Precision, Recall 머신러닝은 데이터 가공/변환, 모델 학습/예측, 그리고 평가(Evaluation)의 프로세스로 구성되어있습니다. 머신러닝 모델은 여러 가지 방법으로 예측 성능을 평가 할 수 있는데, 이 성능 평가 지표(Evaluation Metric)는 일반적으로 모델이 분류(Classification)이냐 회귀(Regression)이냐에 따라 다릅니다. 🎯 회귀와 분류의 성능평가지표들 지도학습 Baseline (기준모델) Evaluation Metric (성능평가지표) Regression (회귀) 실제값과 예측값의 오차 평균값 MAE , MSE, R^2 Classification (분류) Majority(최빈값) Accuracy (정확도) Confusion Matrix (오차행렬) Precision (정밀도) Reca.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.11
타이타닉 (분석연습) * 이번 타이타닉 데이터 분석은 오직 train/test data로만 나눴고, test 결과는 다소 test set에 과적합 되었습니다. 또한 평가지표는 정확도(Accuracy)만 측정되어 정확한 평가가 이루어지지 않았음을 미리 알려드립니다. 1. 분석 배경 1) 데이터 살피기 df = pd.read_csv('train (1).csv') df.head(3) PassengerId : 탑승자 데이터 일련번호 Survived : 생존여부 (0=사망 1=생존) Pclass : 티켓의 선실 등급 (1=일등석 2=이등석 3=삼등석) Name : 탑승자 이름 Sex : 탑승자 성별 Age : 탑승자 나이 SibSp : 같이 탑승한 형제자매 또는 배우자 인원수 Parch : 같이 탑승한 부모님 또는 어린이 인원수 Ti.. 머신러닝 (Machine Learning)/분석 연습 2021.02.11
Model Selection 모듈(학습/테스트 분리,교차검증) 사이킷런 Model Selection 모듈 1. 학습데이터와 테스트 데이터 세트 분리(train_test_split()) 2. 교차 검증 분할 및 평가 3. 하이퍼 파라미터 튜닝을 위한 다양한 함수와 클래스 제공 >> 더 자세한 코드 github https://github.com/gggggeun/study/blob/main/1.%20%EC%82%AC%EC%9D%B4%ED%82%B7%EB%9F%B0(Scikit_learn)/3.%20Scikit-learn%20Model%20Selection%20%EB%AA%A8%EB%93%88.ipynb gggggeun/study Contribute to gggggeun/study development by creating an account on GitHub. githu.. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.10
사이킷런으로 데이터 전처리(결손값,인코딩,스케일) 데이터 전처리(Data Preprocessing)는 머신러닝 알고리즘만큼 중요합니다. 어떻게 전처리해서 어떤 데이터를 입력으로 가지느냐에 따라 결과가 크게 달라지기 때문입니다. 1. 결손값 이 값들은 다른 값으로 변환하던지 없애야합니다. 그럼 어떤 값을 변환해야 하고, 어떤 값을 없애야 할까요? 일반적으로는 아래와 같습니다. Null 값이 많지 않은 Feature : 평균값, 최빈값 등으로 대체 Null 값이 많은 Feature : 해당 Feature 삭제 하지만, 해당 피처의 중요도가 높을 경우엔 단순히 평균값으로 대체하거나 삭제해버리면 옳바른 예측을 할 수 없을 것 입니다. 이럴 경우에는 업무 로직 등을 상세히 검토해 더 정밀한 대체 값을 선정해야 합니다. 결손값은 경우에 따라 데이터 전처리 과정에서.. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.07
사이킷런 기반 프레임워크(3) 사이킷런에 내장된 예제 데이터 세트 내장된 예제 데이터 세트 사이킷런에는 별도의 외부 웹사이트에서 데이터 세트를 내려받을 필요 없이 예제로 활용할 수 있는 간단하면서도 좋은 데이터 세트가 내장되어 있습니다. 이 데이터는 datasets 모듈에 있는 여러 API를 호출해 만들 수 있습니다. fetch 계열의 명령은 데이터의 크기가 커서 패키지에 처음부터 저장돼 있지 않고 인터넷에서 내려받아 홈 디렉터리 아래의 scikit_learn_data라는 서브 디렉터리에 저장한 후 추후 불러들이는 데이터입니다. 따라서 최초 사용 시에 인터넷에 연결돼 있지 않으면 사용할 수 없습니다. 지도학습 예제 데이터의 구성 data는 피처의 데이터 세트를 가리킵니다. target은 분류 시 레이블 값, 회귀일 때는 숫자 결과값 데이터 세트입니다. target_na.. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.07
사이킷런 기반 프레임워크(2) 사이킷런의 주요 모듈 자주쓰이는 핵심 모듈 위주입니다. 분류 모듈명 설명 예제 데이터 sklearn.datasets 사이킷런에 내장되어 예제로 제공하는 데이터 세트 피처 처리 sklearn.preprocessing 데이터 전처리에 필요한 다양한 가공 기능 제공 (인코딩, 정규화, 스케일링 등) sklearn.feature_selection 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 설렉션 작업을 수행하는 다양한 기능 제공 sklearn.feature_extraction sklearn.feature_extraction.text (텍스트데이터) sklearn.feature_extraction.image (이미지 데이터) 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는데 사용함. (예를 들어 텍스트 데이터에서 Cou.. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.07
사이킷런 기반 프레임워크(1) Estimator, fit(), predict() 메서드 Estimator 이해 및 fit(), predict() 메서드 사이킷런은 API 일관성과 개발 편의성을 제공하기 위한 노력이 엿보이는 머신러닝학습에 최적인 패키지입니다. 사이킷런은 머신러닝 모델 학습을 위해서 fit() 메서드와 학습된 모델의 예측을 위해 predict() 메서드를 제공합니다. 사이킷런에서는 분류 알고리즘을 구현한 클래스를 Classifier로, 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭하고, 이 둘을 합쳐 Estimator 클래스라고 부릅니다.(지도학습의 모든 알고리즘을 구현한 클래스를 통칭함) 이 Estimator 클래스는 fit()과 predcict()만을 이용해 간단하게 학습과 예측 결과를 반환합니다. Scikit-learn class 구현 클래스 Estimator.. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.07
사이킷런 특징과 설치법 사이킷런은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다. 파이썬 기반의 머신러닝은 곧 사이킷런으로 개발하는 것을 의미할 정도로 오랜 기간 파이썬 세계에서 인정받았으며, 사이킷런은 파이썬 기반의 머신러닝을 위한 가장 쉽고 효율적인 개발 라이브러리를 제공합니다. 사이킷런 사이트 https://scikit-learn.org/stable/modules/classes.html API Reference — scikit-learn 0.24.1 documentation scikit-learn.org 사이킷런 깃헙 github.com/scikit-learn/scikit-learn scikit-learn/scikit-learn scikit-learn: machine learning in Python. .. 머신러닝 (Machine Learning)/python Scikit-learn library 2021.02.07
분류(Classification) 1. 머신러닝(지도학습) 지도학습은 레이벨(Label) or 타겟(Target) 이라고 하는 명시적인 정답이 있는 데이터가 주어진 상태에서 학습하는 머신러닝 방식입니다. 지도학습은 2종류로 나뉘는데 회귀(Regression)과 분류(Classification) 입니다. 머신러닝(Machine Learning) 지도학습 분류(Classification) 이산 값 (class labels) 회귀(Regression) 연속 값 (number) 비지도학습 ※ 지도학습의 머신러닝 모델 만드는 과정 학습 데이터(Train data)로 주어진 데이터의 Feature와 Target을 머신러닝 알고리즘으로 학습해 모델을 생성(Fit) 하고, 이렇게 생성된 모델에 새로운 데이터 값(Test data)이 주어졌을 때 미지의.. 머신러닝 (Machine Learning)/분류(Classification) 분석 2021.02.04