앙상블(Ensemble)
1. 앙상블 방법들(Ensemble methods) 앙상블은 분류에서 가장 각광받는 알고리즘 방법 중 하나입니다. 딥러닝을 제외한 정형 데이터의 예측 분석 영역에서는 앙상블이 매우 높은 예측 성능으로 인해
gggggeun.tistory.com
앙상블 - 배깅(Bagging)
참고 : KoreaUniv DSBA 영상 다양성(Diversity) Implicit Diversity Explicit Diversity Description 무작위의 서로 다른 training data 여러개를 제공하면 학습 결과도 달라질 것 다른 구성원과 실질적으로 다른..
gggggeun.tistory.com
* 앙상블의 다양성을 높이는 두가지 방법
1) 배깅 2) 예측 변수들을 다양하게 선택
1. 랜덤 포레스트(Random Forest)
랜덤 포레스트는 앙상블 기법들 중에서도 같은 알고리즘(결정트리)으로 여러개의 분류기를 만들어 예측하는 Bagging 방식의 대표적인 알고리즘입니다.
이 알고리즘은 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있습니다. 또한 Boosting 방식과 마찬가지로 기반 알고리즘인 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있습니다.
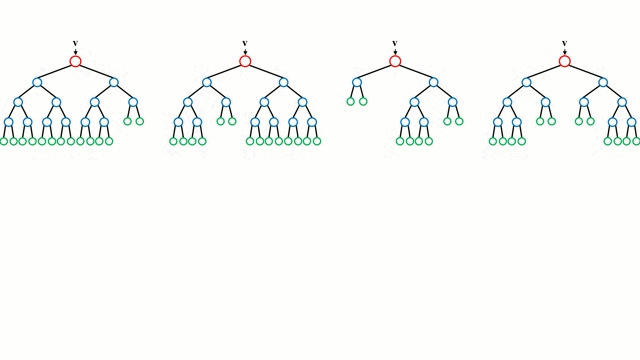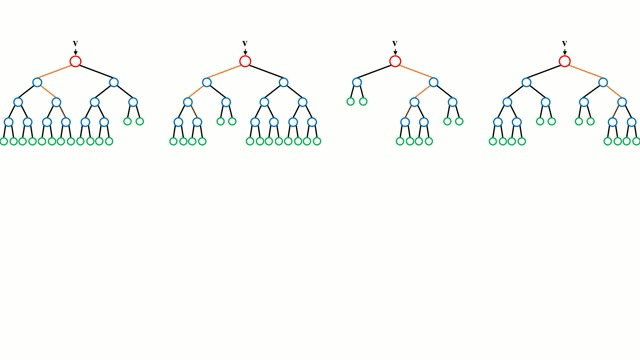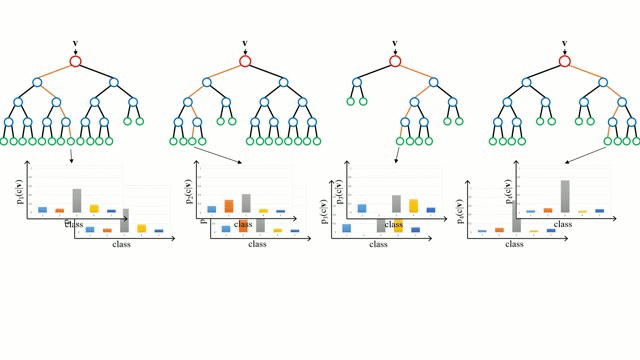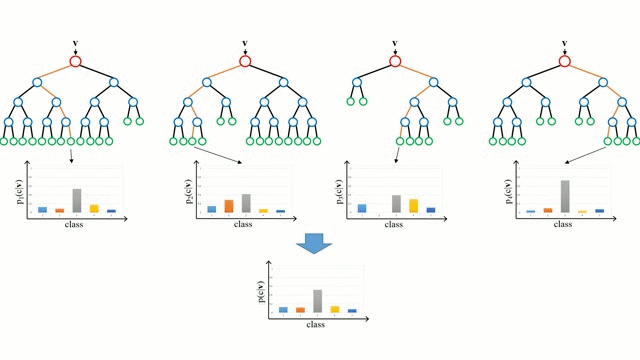
위 그림처럼 랜덤 샘플링된 여러 개의 결정 트리 분류기가 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측을 결정하게 됩니다.
Bagging 은 Bootstrap aggregating(부트스트랩 분할 방식)의 줄임말 입니다.
Bootstrapping이란 여러 개의 데이터 세트를 중첩되게 분리하는 복원 추출 방식(추출하고 다시 제자리에 돌려놓음)을 말합니다. 중복되지 않게 추출되는 교차검증 방식과는 다른 방식입니다. 즉, 랜덤포레스트의 여러 분류기들은 서로 중첩된 데이터를 가지고 있습니다.
| 원래 통계학에서의 부트스트랩은 여러개의 작은 데이터 세트를 임의로 만들어 개별 평균의 분포도를 측정하는 등의 목적을 위한 샘플링 방식을 지칭한다. |
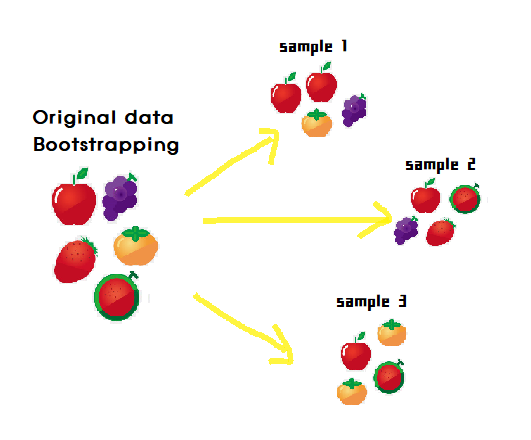
예를들어 랜덤 포레스트를 3개의 결정 트리 기반으로 학습하려 할 때, n_estimators=3 으로 하이퍼 파라미터를 부여하면 됩니다. 또한 random_state로 동일한 예측 결과를 출력합니다.
2. 랜덤포레스트 하이퍼파라미터 (Hyperparameter) 및 튜닝
트리 기반의 앙상블 알고리즘의 단점을 '굳이' 뽑자면 하이퍼 파라미터가 너무 많고, 그로 인해 튜닝을 위한 시간이 많이 소모된다는 것. 그럼에도 예측 성능이 조금만 오를 때 가 있습니다.
트리 기반 자체의 하이퍼 파라미터가 원래 많은 데다 배깅, 부스팅, 학습, 정규화 등을 위한 하이퍼 파라미터까지 추가되므로 일반적으로 다른 머신러닝 알고리즘에 비해 많을 수 밖에 없습니다.
그나마 랜덤 포레스트가 적은 편에 속하는데, 랜덤 포레스트의 대부분의 하이퍼 파라미터는 결정 트리에서 사용했던 것고 같습니다.
# 랜덤포레스트 하이퍼파라미터 종류 보기
print(rf_clf.get_params()){'bootstrap': True, 'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': 'auto', 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_impurity_split': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 10, 'verbose': 0, 'warm_start': False}
* 자주쓰는 몇가지 파라미터
| n_estimators | - 랜덤 포레스트에서 결정 트리의 개수를 지정 (defalt =100) - 많이 설정할수록 좋은 성능을 기대할 수 있지만 계속 증가시킨다고 성능이 무조건 향상되는 것은 아니다. - 늘릴수록 학습 수행 시간이 오래 걸림 |
| n_jobs | 여러개의 CPU 코어가 있는 시스템에서는 모든 CPU 코어를 사용하여 병렬로 RandomForest 트리를 생성하는데 사용. 보통 RandomForest의 fit()을 호출하면 1개 CPU 코어만을 사용하는데. n_jobs=2면 2개 cpu core, n_jobs=-1이면 모든 cpu core를 병렬로 사용하여 n_estimators갯수로 주어진 RandomForest 트리를 병렬로 빠르게 만들어서 학습 수행이 가능합니다. 단 병렬로 트리를 만들어서 학습 수행 속도만 빠르게 하는 방식이다. |
| max_features | - 최적의 분할을 위해 고려할 최대 피처 개수 - defalt = 'auto' 즉, 'sqrt'이다. (결정트리에서의 defalt=None) - 즉, 분할하는 피처를 참조할 때 전체 피처가 아닌 sqrt(전체 피처 제곱근 개수)만큼 참조. (전체피처가 16개라면 분할을 위해 4개 참조) |
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터 수 - 과적합을 제어함 - defalt =2 - 작게 설정할수록 분할되는 노드가 많아져서 과적합 가능성 증가 |
| min_samples_leaf | - 말단 노드(leaf)가 되기 위한 최소한의 샘플 데이터 수 - min_samples_split과 유사하게 과적합 제어 용도. - 비대칭적(imbalanced) 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요. |
| max_depth | - 트리의 최대 깊이를 규정 - defalt = None (완벽하게 클래스 결정 값이 될 때까지 계속 분할 or 노드가 가지는 데이터 개수가 min_samples_split보다 작아질 때까지 계속 깊이를 증가) |
| max_leaf_nodes | - 말단 노드(Leaf)의 최대 개수 |
'머신러닝 (Machine Learning) > 분류(Classification) 분석' 카테고리의 다른 글
| 앙상블 - 배깅(Bagging) (0) | 2021.03.01 |
|---|---|
| 앙상블 - 보팅(Voting) (0) | 2021.02.21 |
| 앙상블(Ensemble) (0) | 2021.02.21 |
| 분류 관련 Youtube (0) | 2021.02.14 |
| 결정 트리의 과적합 (Overfitting) 시각화로 이해하기 (0) | 2021.02.14 |