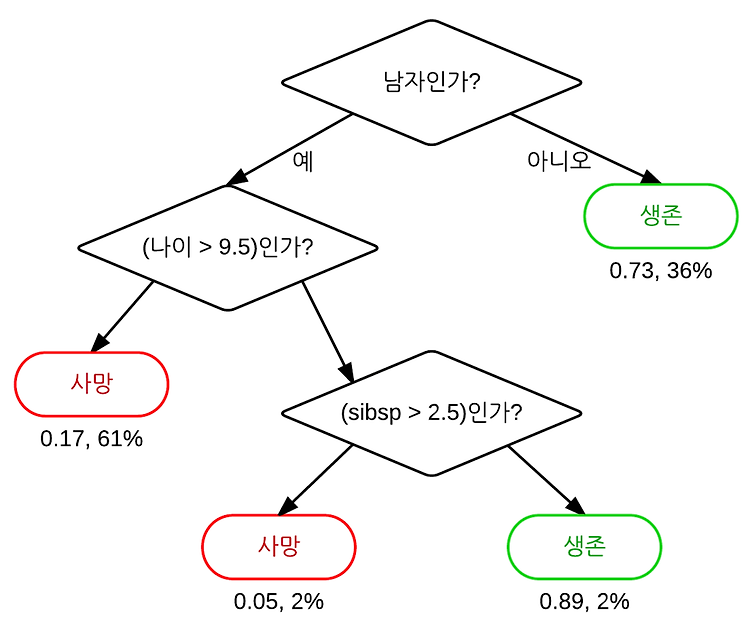
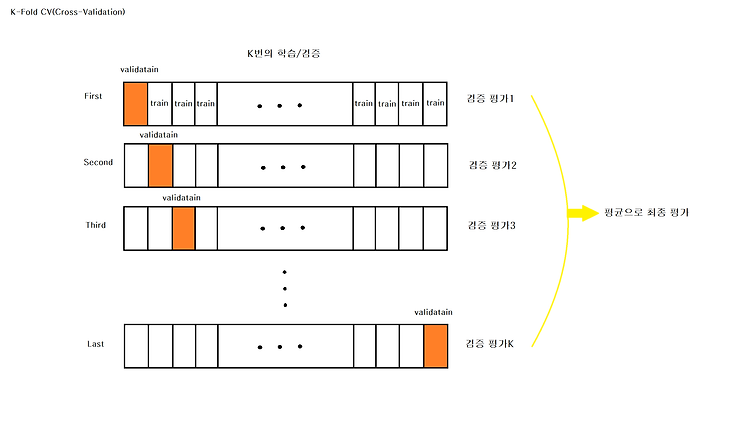
1. 보팅 방법 (voting methods) 하드 보팅(Hard Voting) 소프트 보팅(Soft Voting) 최빈값 평균값 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정 만약 레이블 값이 2개일 때, 레이블 1번 과 레이블 2번 중 다수의 레이블로 예측. 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정. 일반적으로 이 방법을 사용함. 만약 레이블 값이 2개일 때, 레이블 값이 1번인 경우의 확률의 평균과 레이블 값이 2번인 경우의 확률의 평균 중 높은 평균의 레이블로 예측. 일반적으로 하드 보팅보다는 소프트 보팅의 예측 성능이 좋아 더 많이 사용된다. 2. Result Aggregatin..